
En una nueva patente de AMD, los investigadores han destacado técnicas para realizar operaciones de aprendizaje automático utilizando uno o más chiplets de acelerador ML dedicados. El dispositivo resultante se denomina Dispositivo de procesamiento acelerado o APD que se puede utilizar tanto para juegos como para GPU de centros de datos a través de diferentes implementaciones.
El método implica configurar una parte de la memoria chiplet como caché mientras que la otra se configura como memoria de acceso directo.
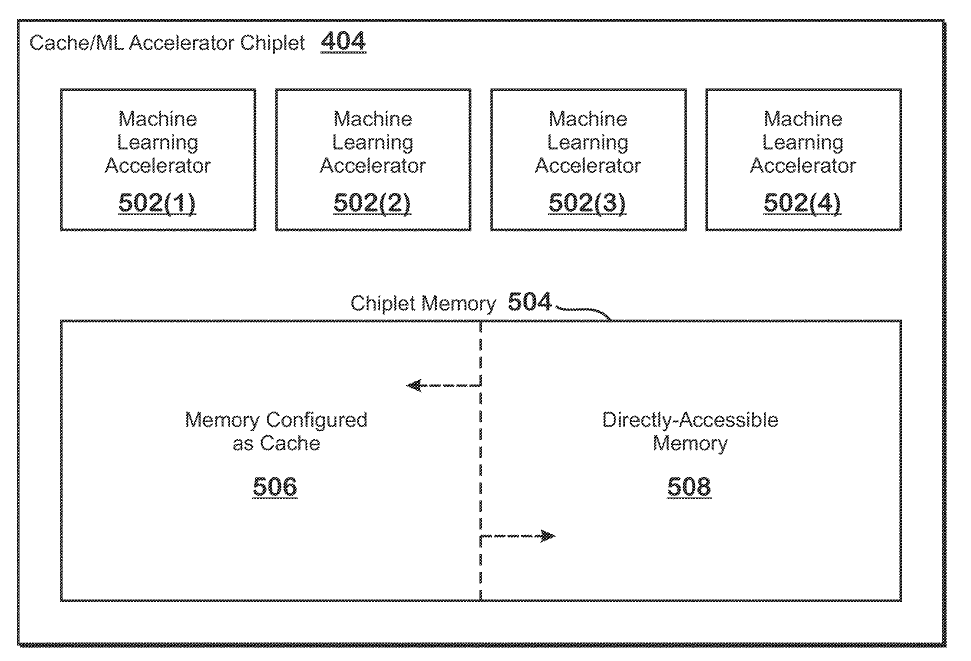
Los aceleradores de aprendizaje automático utilizan la subparte del primero en el mismo chiplet para realizar operaciones de aprendizaje automático. La patente es muy abierta con respecto a sus usos, lo que indica un posible uso en CPU, GPU u otros dispositivos de almacenamiento en caché, pero el objetivo principal parece ser GPU con varios miles de unidades SIMD.
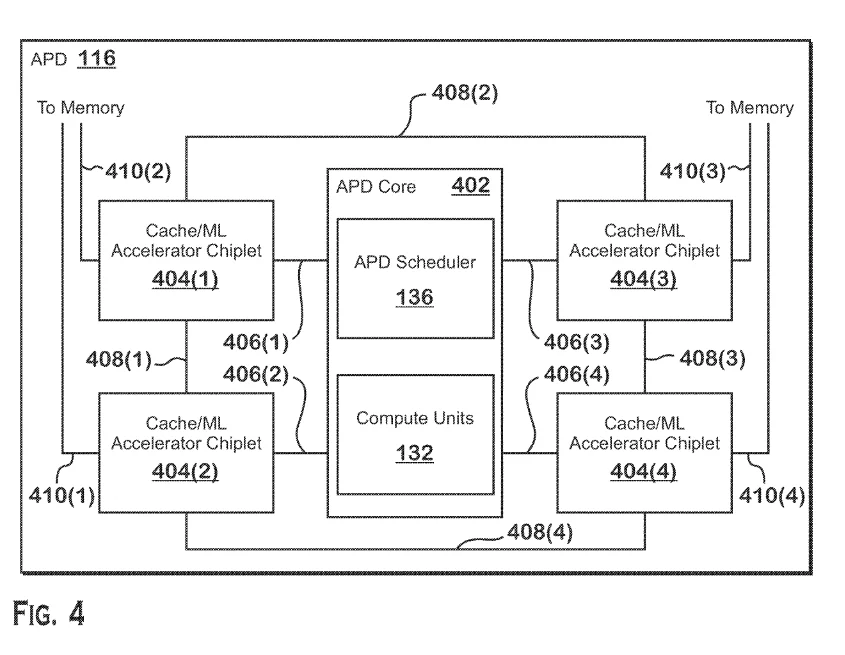
Una implementación del APD está configurado para aceptar comandos a través de chips gráficos y canalizaciones de cómputo desde el procesador de comandos, lo que muestra la capacidad tanto de renderizar gráficos como de las cargas de trabajo de cómputo intensivo requeridas por las redes de convolución.
El APD contiene varios SIMD capaces de realizar operaciones vectoriales junto con tareas escalares y SP limitadas similares a las GPU AMD existentes.
Algunas implementaciones pueden incluir circuitos de multiplicación de matrices, mientras que otras implementaciones pueden presentar chiplets de acelerador de caché / aprendizaje automático en troqueles físicos separados que el núcleo APD fabricado con un nodo más maduro que el núcleo.
La memoria en los chiplets ML se puede cambiar entre memoria caché para el núcleo APD o como caché / memoria directa para almacenar los resultados de entrada y salida de las operaciones realizadas por los aceleradores ML.
Hay opciones para permitir que parte de la memoria se use como una y el resto como la otra y viceversa.
Además, la memoria caché en los chiplets ML también se puede usar como caché L3 para el núcleo APD (GPU), o como interfaz física entre el núcleo APD y la memoria más arriba (más cerca) de la GPU. En general, el chiplet ML y su memoria son altamente configurables, lo que permite diversas cargas de trabajo.
Fuente: Freepatentsonline



