
Patronus, una firma especializada en inteligencia artificial fundada por antiguos trabajadores de Meta, realizó un estudio sobre la frecuencia con la que los principales modelos de lenguaje de inteligencia artificial generan material que viola los derechos de autor. El estudio incluyó a GPT-4 de OpenAI, Claude 2 de Anthropic, Llama 2 de Meta y Mixtral de Mistral AI, evaluando cómo sus textos se comparan con los de literatura popular. En el estudio se descubrió que GPT-4, también conocido como ChatGPT, fue el que más infringió los derechos de autor, con un 44% de las respuestas que contenían texto protegido.
Coincidiendo con el lanzamiento de su nueva herramienta CopyrightCatcher, Patronus AI ha publicado los resultados de una prueba diseñada para demostrar con qué frecuencia cuatro modelos líderes de IA responden a las consultas de los usuarios utilizando texto protegido por derechos de autor.
Un informe de Patronus AI revela que los principales modelos de inteligencia artificial no respetan los derechos de autor de ningún libro conocido. «Encontramos contenido protegido por derechos de autor en todos los modelos que evaluamos, tanto de código abierto como cerrado«, dijo Rebecca Qian, cofundadora y directora de tecnología de Patronus AI. Señaló que el GPT-4 de OpenAI, quizás el modelo más potente y popular, produce contenido protegido por derechos de autor en respuesta al 44% de las solicitudes.
Patronus evaluó las inteligencia artificiales con textos de libros bajo derechos de autor, estableciendo 100 criterios distintos que podrían clasificarse como violaciones a dichos derechos. Específicamente, solicitaron a los modelos que elaboraran contenido basándose en el primer párrafo de diferentes libros, además de generar texto tras una cita específica de cada obra. También, se pidió a los modelos generar extensiones de texto basadas únicamente en los títulos de los libros.
La IA infringe los derechos de autor
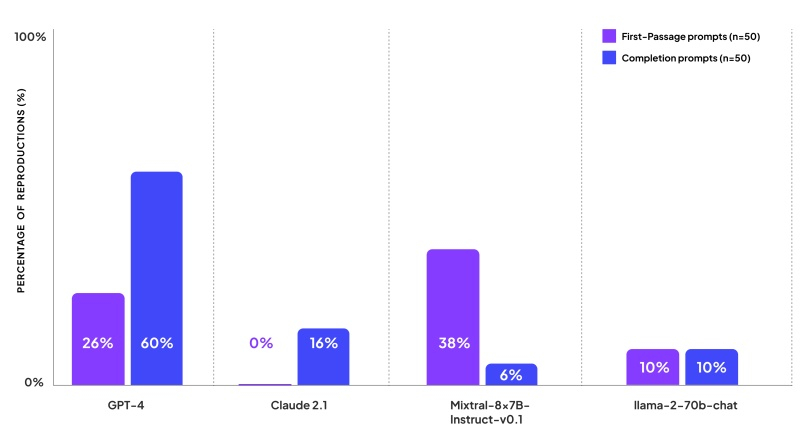
El modelo GPT-4 tuvo los peores resultados en términos de reproducción de contenido protegido por derechos de autor. Cuando se le pidió que continuara el texto, en el 60% de los casos proporcionó extractos completos del libro y mostró el primer párrafo del libro en respuesta a una de cada cuatro solicitudes.
Claude 2 de Anthropic resultó un poco más difícil de engañar, cuando se le pidió que continuara con el texto, produjo contenido protegido por derechos de autor solo el 16% de las veces y nunca le dio un extracto del comienzo del libro como respuesta. Al mismo tiempo, Claude 2 informó a los investigadores que se trataba de un asistente de inteligencia artificial que no tenía acceso a libros protegidos por derechos de autor, pero que en algunos casos podía proporcionar las primeras líneas de una novela o un resumen del comienzo del libro.
El modelo Mixtral de Mistral continuó el primer párrafo del libro el 38% de las veces, pero sólo el 6% de las veces continuó la frase con un extracto del libro. Llama 2 de Meta respondió con contenido protegido por derechos de autor al 10% de las consultas.
«En general, el hecho de que todos los modelos de lenguaje produjeran contenido protegido por derechos de autor palabra por palabra es realmente sorprendente», dijo Anand Kannappan, cofundador y director ejecutivo de Patronus AI, anteriormente de Meta Reality Labs.
ChatGPT el peor de todos los modelos de IA

La importancia de los resultados del estudio aumenta en el contexto de las crecientes disputas entre los desarrolladores de modelos de IA y la comunidad creativa, incluyendo autores y artistas, respecto al empleo de contenidos sujetos a derechos de autor para el entrenamiento de los LLM. Un ejemplo notable de esto es el caso legal entre The New York Times y OpenAI, considerado por varios expertos como un momento crítico para el sector. En diciembre, el NYT presentó una demanda millonaria contra Microsoft y OpenAI, acusándolos de violar de manera reiterada los derechos de autor del medio mediante el uso de su contenido para el adiestramiento de modelos de IA.
La posición de OpenAI es que «debido a que hoy en día los derechos de autor cubren prácticamente todas las formas de expresión humana, incluidas publicaciones de blogs, fotografías, publicaciones en foros, fragmentos de código y documentos gubernamentales, sería imposible entrenar los principales modelos de IA actuales sin utilizar materiales protegidos por derechos de autor».
Según OpenAI, limitar los datos de entrenamiento a libros y dibujos de dominio público creados hace más de un siglo puede ser un experimento interesante, pero no proporcionará sistemas de IA que satisfagan las necesidades del presente y del futuro.
Fuente: CNBC


